
※ 공부 내용의 복습 개념으로 정리된 글입니다. - 출처 시나공
반정규화의 개념
반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위입니다.
- 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성은 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있습니다.
- 과도한 반정규화는 오히려 성능을 저하시킬 수 있습니다.
- 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 합니다.
- 반정규화 방법에는 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있습니다.
테이블 통합
테이블 통합은 두 개의 테이블이 조인(Join)되는 경우가 많아 하나의 테이블로 합쳐 사용하는 것이 성능 향상에 도움이 될 경우 수행합니다.
- 두 개의 테이블에서 발생하는 프로세스가 동이랗게 자주 처리되는 경우, 두 개의 테이블을 이용하여 항상 조회를 수행하는 경우 테이블 통합을 고려합니다.
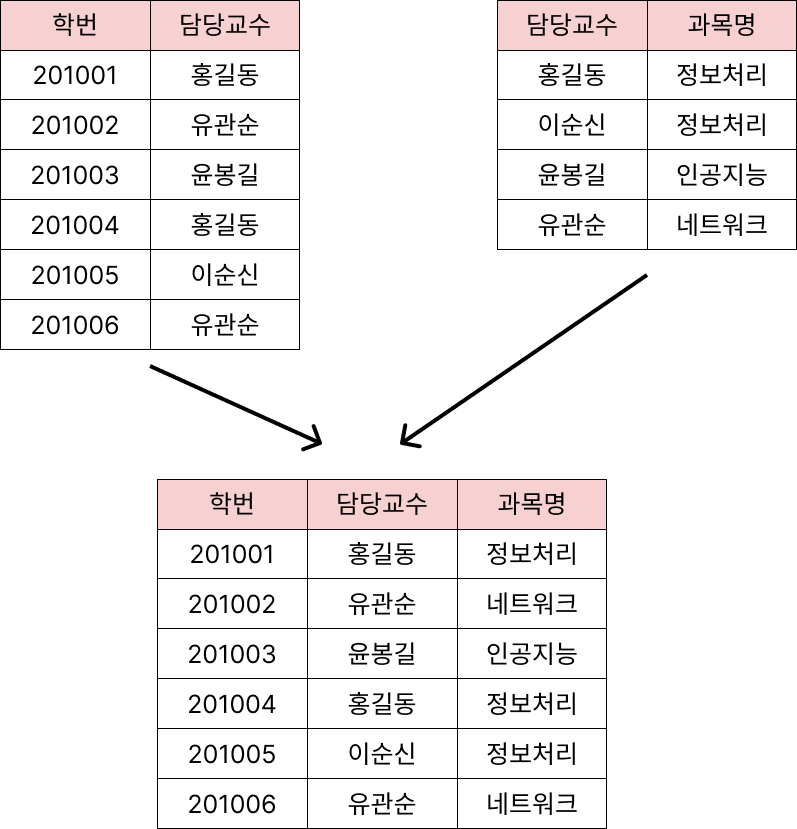
- 테이블 통합의 종류에는 1 : 1 관계 테이블 통합, 1 : N 관계 테이블 통합, 슈퍼타입/서브타입 테이블 통합이 있습니다.
- 테이블 통합 시 고려 사항
- 데이터 검색은 간편하지만 레코드 증가로 인해 처리량이 증가합니다.
- 테이블 통합으로 인해 입력, 수정, 삭제 규칙이 복잡해질 수 있습니다.
- Not Null., Default, Check 등의 제약조건(Constraint)을 설계하기 어렵습니다.
※ 슈퍼타입/서브타입
슈퍼타입은 상위 개체를, 서브타입은 하위 개체를 의미합니다.
※ Not Null
속성 값이 Null이 될 수 없음
※ Default
속성 값이 생략되면 기본값 설정
※ Check
속성 값의 범위나 조건을 설정하여 설정한 값만 허용
테이블 분할
테이블 분할은 테이블을 수직 또는 수평으로 분할하는 것입니다.
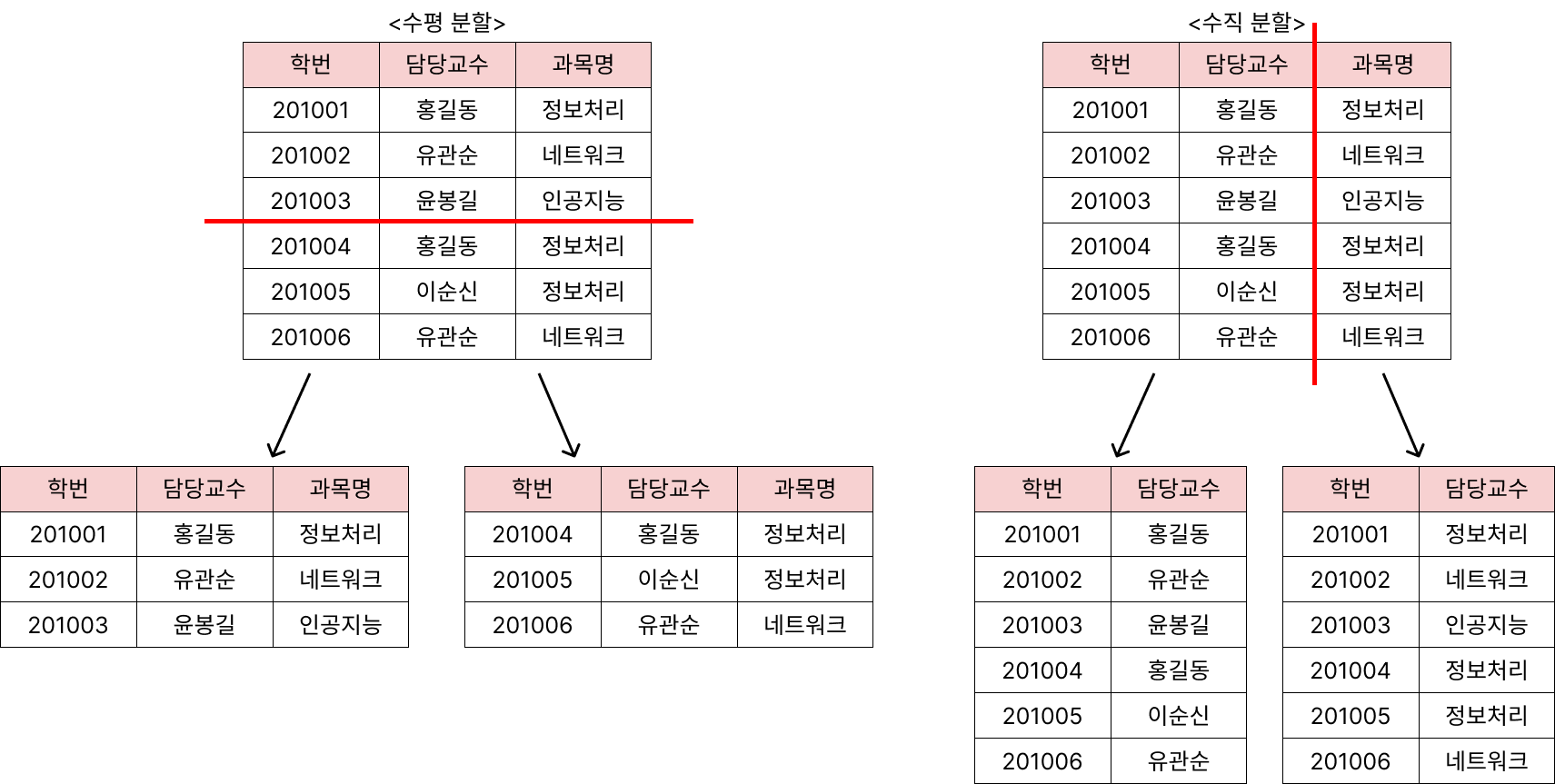
- 수평 분할(Horizontal Partitioning)
- 수평 분할은 레코드(Record)를 기준으로 테이블을 분할하는 것입니다.
- 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할합니다.
- 수직 분할(Vertical Partitioning)
- 수직 분할은 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것입니다.
- 갱신 위주의 속성 분할 : 데이터 갱신 시 레코드 잠금으로 인해 다른 작업을 수행할 수 없으므로 갱신이 자주 일어나는 속성들을 수직 분할하여 사용합니다.
- 자주 조회되는 속성 분할 : 테이블에서 자주 조회되는 속성이 극히 일부일 경우 자주 사용되는 속성들을 수직 분할하여 사용합니다.
- 크기가 큰 속성 분할 : 이미지나 2GB 이상 저장될 수 있는 텍스트 형식 등으로 된 속성들을 수직 분할하여 사용합니다.
- 보안을 적용해야 하는 속성 분할 : 테이블 내의 특정 속성에 대해 보안을 적용할 수 없으므로 보안을 적용해야 하는 속성들을 수직 분할하여 사용합니다.
예 : 수직 분할 수행의 예

- 테이블 분할 시 고려 사항
- 기본키의 유일성 관리가 어려워집니다.
- 데이터 양이 적거나 사용 빈도가 낮은 경우 테이블 분할이 필요한지를 고려해야합니다.
- 분할된 테이블로 인해 수행 속도가 느려질 수 있습니다.
- 데이터 검색에 중점을 두어 테이블 분할 여부를 결정해야 합니다.
※ 레코드 잠금
레코드 잠금은 데이터의 무결성을 유지하기 위해 어떤 프로세스가 데이터 값을 변경하려고 하면 변경 작업이 완료될 때까지 다른 프로세스가 해당 데이터 값을 변경하지 못하도록 하는 것을 의미합니다.
중복 테이블 추가
여러 테이블에서 데이터를 추출해서 사용해야 하거나 다른 서버에 저장된 테이블을 이용해야 하는 경우 중복 테이블을 추가하여 작업의 효율성을 향상시킬 수 있습니다.
- 중복 테이블을 추가하는 경우
- 정규화로 인해 수행 속도가 느려지는 경우
- 많은 범위의 데이터를 자주 처리해야 하는 경우
- 특정 범위의 데이터만 자주 처리해야 하는 경우
- 처리 범위를 줄이지 않고는 수행 속도를 개선할 수 없는 경우
- 중복 테이블을 추가하는 방법은 다음과 같습니다.
- 집계 테이블의 추가 : 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거(Trigger)를 설정하여 사용하는 것으로, 트리거의 오버헤드(Overhead)에 유의해야 합니다.
- 진행 테이블의 추가 : 이력 관리 등의 목적으로 추가하는 테이블로, 적절한 데이터 양의 유지와 활용도를 높이기 위해 기본키를 적절히 설정합니다.
- 특정 부분만을 포함하는 테이블의 추가 : 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성합니다.
예 : 집계 테이블 추가
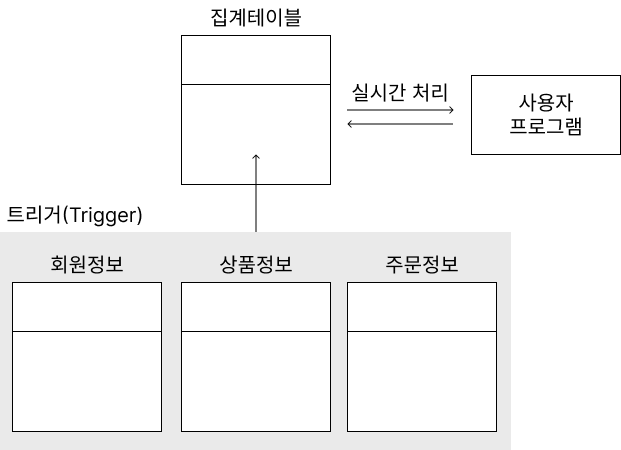
※ 트리거(Trigger)
트리거는 데이터베이스 시스템에서 데이터의 입력, 갱신, 삭제 등의 이벤트(Event)가 발생할 때마다 자동적으로 수행되는 절차형 SQL입니다.
※ 이벤트(Event)
시스템에 어떤 일이 발생한 것을 말하여, 트리거에서 이벤트는 데이터의 입력, 갱신, 삭제와 같이 데이터를 조작하는 작업이 발생했음을 의미합니다.
※ 이력 관리
이력 관리는 속성 값의 변화를 관리하기 위해 테이블에서 특정 속성 값이 변경될 때마다 변경되기 전의 속성 값을 저장하는 것을 말합니다.
중복 속성 추가
중복 속성 추가는 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것입니다.
- 중복 속성을 추가하면 데이터의 무결성 확보가 어렵고, 디스크 공간이 추가로 필요합니다.
예 : 중복 속성 추가
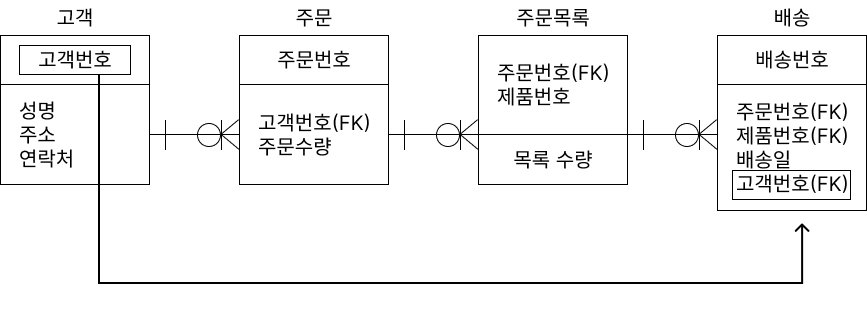
- 중복 속성을 추가하는 경우
- 조인이 자주 발생하는 속성인 경우
- 접근 경로가 복잡한 속성인 경우
- 액세스의 조건으로 자주 사용되는 속성인 경우
- 기본키의 형태가 적절하기 않거나 여러 개의 속성으로 구성된 경우
- 중복 속성 추가 시 고려 사항
- 테이블 중복과 속성의 중복을 고려합니다.
- 데이터 일관성 및 무결성에 유의해야 합니다.
- SQL 그룹 함수를 이용하여 처리할 수 있어야 합니다.
- 저장 공간의 지나친 낭비를 고려합니다.
'정보처리산업기사' 카테고리의 다른 글
| 정보처리산업기사 - 데이터베이스 이해 - 뷰(View) (0) | 2024.09.19 |
|---|---|
| 정보처리산업기사 - 데이터베이스 이해 - 인덱스(Index) (0) | 2024.09.18 |
| 정보처리산업기사 - 데이터베이스 이해 - 정규화(Normalization) (1) | 2024.09.16 |
| 정보처리산업기사 - 데이터베이스 이해 - 관계대수 및 관계해석 (0) | 2024.09.15 |
| 정보처리산업기사 - 데이터베이스 이해 - 관계형 데이터베이스의 제약 조건 - 무결성 (1) | 2024.09.14 |