
※ 공부 내용의 복습 개념으로 정리된 글입니다. - 출처 시나공
일반 형식
SELECT [PREDICATE] [테이블명.]속성명 [AS 별명][, [테이블명.]속성명, ...]
[, 그룹함수(속성명) [AS 별칭]]
[, WINDOW함수 OVER (PARTITION BY 속성명1, 속성명2, ... ORDER BY 속성명3, 속성명4, ...) [AS 별칭]]
FROM 테이블명[, 테이블명, ...]
[WHERE 조건]
[GROUP BY 속성명, 속성명, ...]
[HAVING 조건]
[ORDER BY 속성명 [ASC | DESC]];- 그룹함수 : GROUP BY절에 지정된 그룹별로 속성의 값을 집계할 함수를 기술합니다.
- WINDOW 함수 : GROUP BY절을 이용하지 않고 속성의 값을 집계할 함수를 기술합니다.
- PARTITION BY : WINDOW 함수가 적용될 범위로 사용할 속성을 지정합니다.
- ORDER BY : PARTITION 안에서 정렬 기준으로 사용할 속성을 지정합니다.
- GROUP BY절 : 특정 속성을 기준으로 그룹화하여 검색할 때 사용합니다. 일반적으로 GROUP BY절은 그룹 함수와 함께 사용됩니다.
- HAVING절 : GROUP BY와 함께 사용되며, 그룹에 대한 조건을 지정합니다.
그룹 함수 / WINDOW 함수
그룹 함수
GROUP BY절에 지정된 그룹별로 속성의 값을 집계할 때 사용됩니다.
- COUNT(속성명) : 그룹별 튜플 수를 구하는 함수.
- SUM(속성명) : 그룹별 합계를 구하는 함수
- AVG(속성명) : 그룹별 평균을 구하는 함수
- MAX(속성명) : 그룹별 최대값을 구하는 함수
- MIN(속성명) : 그룹별 최소값을 구하는 함수
- STDDEV(속성명) : 그룹별 표준편차를 구하는 함수
- VARIANCE(속성명) : 그룹별 분산을 구하는 함수
- ROLLUP(속성명, 속성명, ...)
- 인수로 주어진 속성을 대상으로 그룹별 소계를 구하는 함수입니다.
- 속성의 개수가 n개이면, n + 1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계됩니다.
- CUBE(속성명, 속성명, ...)
- ROLLUP과 유사한 형태이나 CUBE는 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 구합니다.
- 속성의 개수가 n개이면, 2ⁿ 레벨까지, 상위 레벨에서 하위 레벨 순으로 데이터가 집계됩니다.
WINDOW 함수
- GROUP BY절을 이용하지 않고 함수의 인수로 지정한 속성을 범위로 하여 속성의 값을 집계합니다.
- 함수의 인수로 지정한 속성이 대상 레코드의 범위가 되는데, 이를 윈도우(WINDOW)라고 부릅니다.
- WINDOW 함수
- ROW_NUMBER() : 윈도우별로 각 레코드에 대한 일련 번호를 반환합니다.
- RANK() : 윈도우별로 순위를 반환하며, 공동 순위를 반영합니다.
- DENSE_RANK() : 윈도우별로 순위를 반환하며, 공동 순위를 무시하고 순위를 부여합니다.
※ WINDW 함수가 적용될 범위
GROUP BY 절에 지정한 속성이 그룹 함수의 범위로 사용되듯이 PARTITION BY 절에 지정한 속성이 WINDOW 함수의 범위로 사용됩니다.
WINDOW 함수 이용 검색
GROUP BY절을 이용하지 않고 함수의 인수로 지정한 속성을 범위로 하여 속성의 값을 집계합니다.
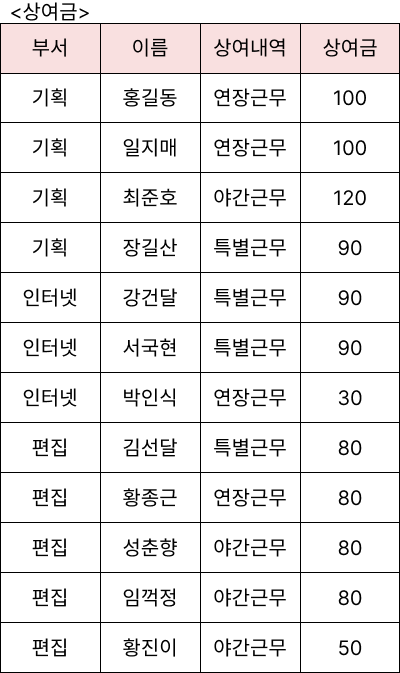
예제1
<상여금> 테이블에서 '상여내역'별로 '상여금'에 대한 일련 번호를 구하시오.
(단, 순서는 내림차순이며 속성명은 'NO'로 할 것)
SELECT
상여내역,
상여금,
ROW_NUMBER() OVER (PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS NO
FROM 상여금;
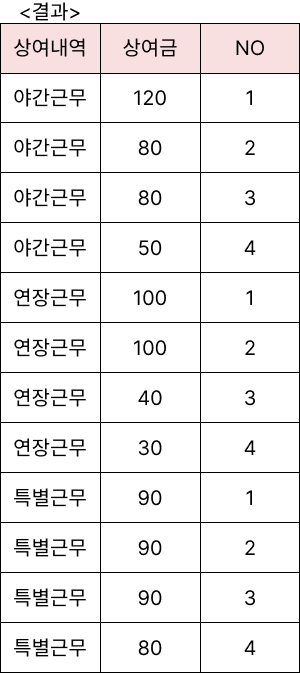
예제2
<상여금> 테이블에서 '상여내역'별로 '상여금'에 대한 순위를 구하시오.
(단, 순서는 내림차순이며, 속성명은 '상여금순위'로 하고, RANK() 함수를 이용할 것)
SELECT
상여내역.상여금,
RANK() OVER (PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS 상여금순위
FROM 상여금;
그룹 지정 검색
GROUP BY절에 지정한 속성을 기준으로 자료를 그룹화하여 검색합니다.
예제1
<상여금> 테이블에서 '부서'별 '상여금'의 평균을 구하시오.
SELECT
부서,
AVG(상여금) AS 평균
FROM
상여금
GROUP BY 부서;

예제2
<상여금> 테이블에서 부서별 튜플 수를 검색하시오.
SEELECT
부서,
COUNT(*) AS 사원수
FROM 상여금
GROUP BY 부서;

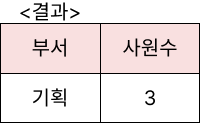
예제3
<상여금> 테이블에서 '상여금'이 100이상인 사원이 2명 이상인 '부서'의 튜플 수를 구하시오.
SELECT
부서,
COUNT(*) AS 사원수
FROM 상여금
WHERE 상여금 >= 100
GROUP BY 부서
HAVING COUNT(*) >= 2;
예제4
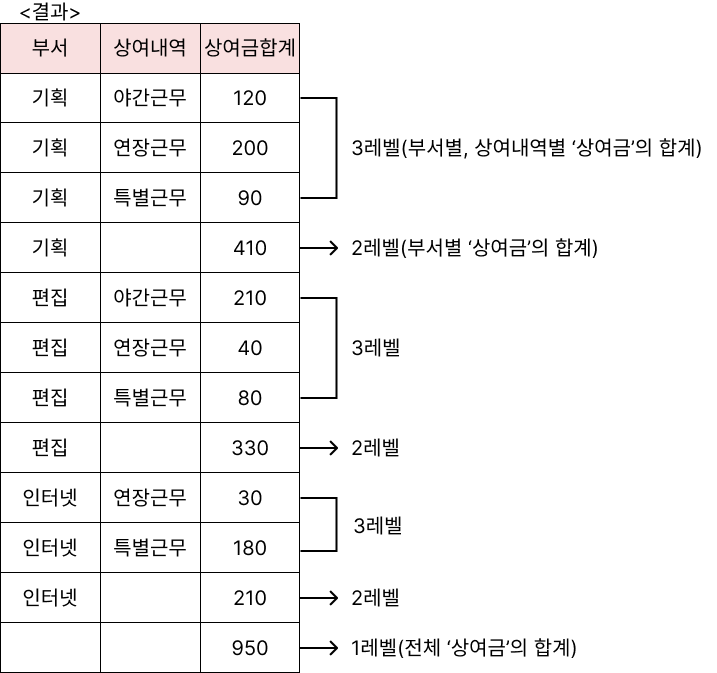
<상여금> 테이블의 '부서', '상여내역', 그리고 '상여금'에 대해 부서별 상여내력별 소계와 전체 합계를 검색하시오.
(단, 속성명은 '상여금합계'로 하고, ROLLUP 함수를 사용할 것)
SELECT
부서,
상여내역,
SUM(상여금) AS 상여금합계
FROM 상여금
GROUP BY ROLLUP(부서, 상여내역);
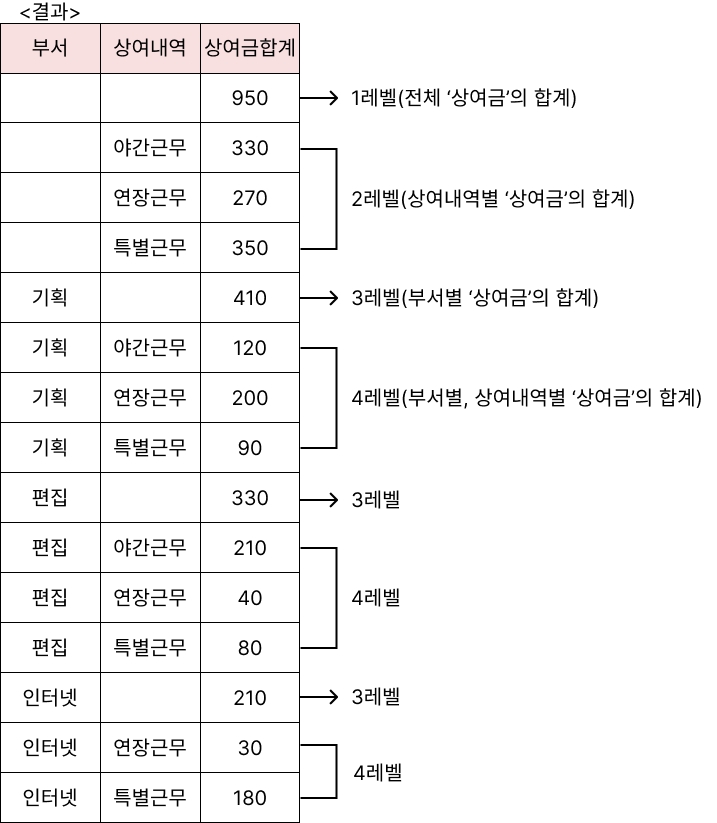
예제5
<상여금> 테이블의 '부서', '상여내역', 그리고 '상여금'에 대해 부서별 상여내역별 소계와 전체 합계를 검색하시오.
(단, 속성명은 '상여금합계'로 하고, CUBE 함수를 사용할 것)
SELECT 부서, 상여내역, SUM(상여금) AS 상여금합계
FROM 상여금
GROUP BY CUBE(부서, 상여내역);
집합 연산자를 이용한 통합 질의
집합 연산자를 사용하여 2개 이상의 테이블의 데이터를 하나로 통합합니다.
표기 형식
SELECT 속서명1, 속성명2, ...
FROMM 테이블명
UNION | UNION ALL | INTERSECT | EXCEPT
SELECT 속성명1, 속성명2, ...
FROM 테이블명
[ORDER BY 속성명 [ASC | DESC]];- 두 개의 SELECT문에 기술한 속성들을 개수와 데이터 유형이 서로 동일해야 합니다.
집합 연산자의 종류(통합 질의의 종류)

예제1
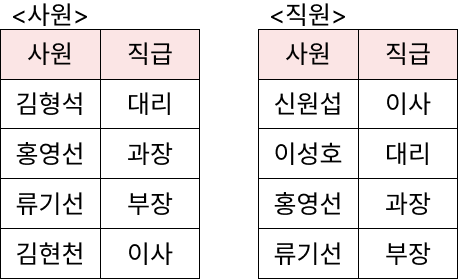
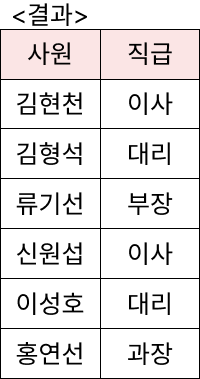
<사원> 테이블과 <직원> 테이블을 통합하는 질의문을 작성하시오.
(단, 같은 레코드가 중복되어 나오지 않게 하시오.)
SELECT *
FROM 사원
UNION
SELECT *
FROM 직원;
예제2
<사원> 테이블과 <직원> 테이블에 공통으로 존재하는 레코드만 통합하는 질의문을 작성하시오.
SELECT *
FROM 사원
INTERSECT
SELECT *
FROM 직원;
'정보처리산업기사' 카테고리의 다른 글
| 정보처리산업기사 - 데이터베이스 프로그래밍 - 절차형 SQL (0) | 2024.09.25 |
|---|---|
| 정보처리산업기사 - SQL 활용 - DML - JOIN (0) | 2024.09.24 |
| 정보처리산업기사 - SQL 활용 - DML - SELECT - 1 (3) | 2024.09.22 |
| 정보처리산업기사 - SQL 활용 - DML (0) | 2024.09.21 |
| 정보처리산업기사 - SQL 활용 - DCL (0) | 2024.09.21 |